自从疫情开始,节假日基本就废了,来去也要各种报备、审批、核酸,还是在深圳蹲着算了,用中秋节刷了一本书 《Learning Elasticsearch 7.x》。
在互联网界经常会听到 ELK、EFK 这类的称呼,指代目前最流行的开源日志系统架构,其中的 E 就是 Elasticsearch,它负责最核心的搜索功能。提到搜索,不得不联想到超级巨头谷歌,以及这两年日子越来越不好过的国内小巨头百度,搜索可都是他们当年的成名绝技。在如今这个信息满天飞的时代,对于个人来说,如何检索信息是一项必备的生存技能,因为获取到信息质量的高低直接影响决策质量的高低。而对公司来说,如何整合信息以更好地服务于市场上的大小用户也是生死攸关的大事。so,E 君是非常重要的。
E 是基于 Lucene 库(一个高性能的开源搜索引擎)的一个包装,提供了方便的 restful API,并扩展了对分布式的支持。
E 目前主要用于几个领域:数据搜索、日志分析、应用性能监控、系统性能监控、数据可视化。使用方式主要有三种:1)作为主力数据源,如博客系统;2)作为次要的面向搜索的数据源,主力数据库的写入变化需要通过其他方式同步到 E,如 mysql 的 binlog 之类;3)作为独立系统,如 EFK。
E 也是集群化部署,Node 节点有4种角色可以分配:Master、Data、Ingest、Machine Learning。Master,管理节点;Data,数据节点;Ingest,在被索引之前丰富和转换数据用的;Machine Learning,支持跑机器学习的任务。
进一步需要理解 E 的几个概念:index、mapping、shard、segment、document、field。index 是最上层的开发者直接操作的概念,index 往下分为多个 shard,每个 shard 对应到 lucene 里的一个 lucene index,lucene index 又可以分为多个 segment,每个 segment 都是一个 inverted index(倒排索引),每个 segment 可以包含多个 document,document 以 json 格式存放数据,每个 document 中包含多个 field,而 mapping 规定了 document 中每个 field 的类型。和关系型数据库可以做这样的类比:index 类似于数据库或者表,document 类似于一行记录,field 类似于字段,mapping 则类似于表定义。在搭建好的 E 中,我们操作 API 时直接关心的是 index、document。
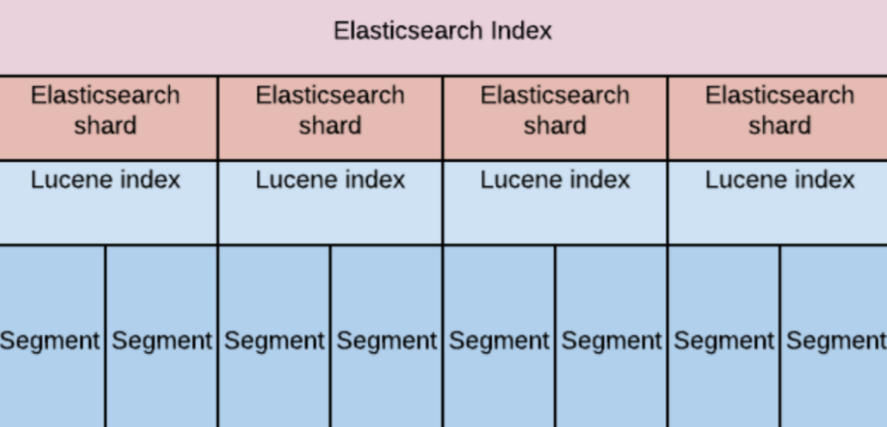
随便拿起身旁的一件物品,从原材料到制成产品再到销售到你手上,必定经历了很多个环节,E 也是这样,从原始数据到搜索结果也分了:数据准备、创建索引关系、搜索语法、结果聚合这几个关键环节。
概念的现实对应物总是充满了粗糙的细节,所以在收集到原始数据后需要对其进行规整(所以很多大数据的第一步就是清洗数据,如果是手工,那也算一种人工智能了吧…),在数据准备阶段需要应用 Analyzer 对数据进行处理,每个 Analyzer 由三种元素组成:character filter、tokenizer、token filter。也就是先对 character 做处理,过滤掉一些没用的,再做成 token,再对 token 进行过滤处理。(说起这个想起以前本科做过的编译器,也分词法分析、语法分析、语义分析,在词法分析阶段就是把单词一个个摘出来,用单个空格分隔,然后语法分析阶段匹配,再生成语义分析树。改天再研究下自己当初写的代码)
对于 Analyzer,已经内置了不少常用的,除了直接用内置的,也可以自定义,但自定义的 Analyzer 必须至少包含一个 tokenizer。
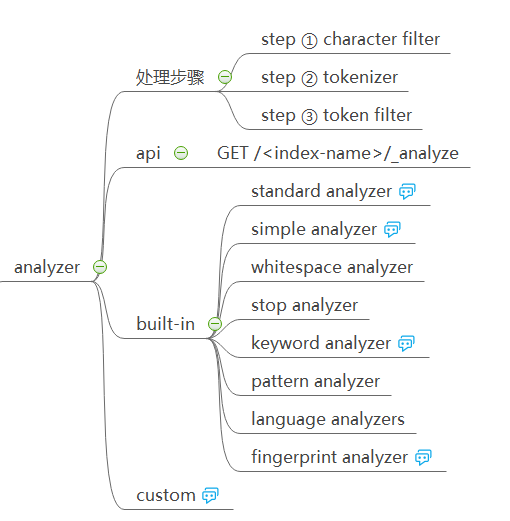
对于预处理的 character filter、tokenizer、token filter 这些细节就不展开了,纯粹体力活,建议去官网看一手最新的。
接下来就是核心的 index,E 的一大卖点就是提供了方便的 restful api 操作 index,如下导图所示:
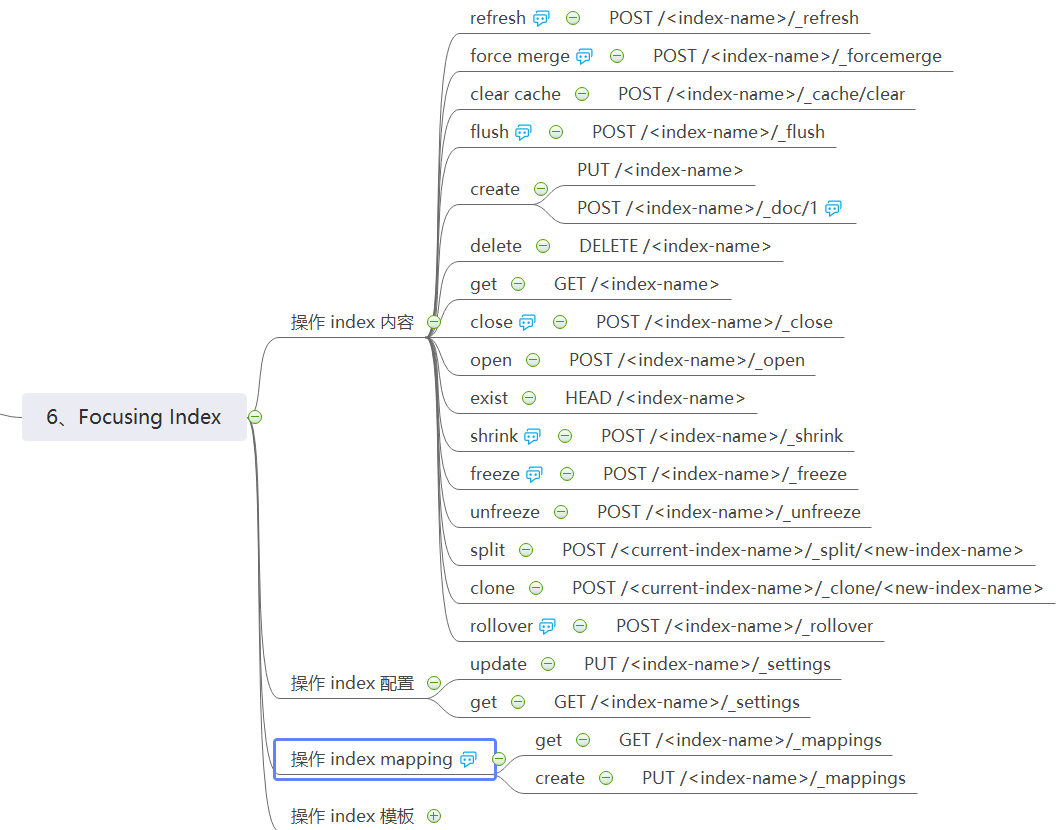
从上图看来,对 index 的基本操作都提供了 restful api,确实非常方便。我们知道 restful api 最标准的玩法就是通过 http 协议的几大动作(GET、PUT、POST、DELETE、…),来管理资源(名词),应付 CRUD 程序,那自然绰绰有余,但 E 操作 index 的语义明显复杂一些,所以在结合 restful 的情况下又在 url 中放了一些特殊语义的动作,以 _xxx 这样的方式命名。
索引操作除了常用的 CRUD,还有索引拆分、冻结/解冻、克隆、滚动、压缩、关闭、刷新、合并等,细节还是不展开了,去官网看。
索引的目的是为了最终给用户搜索,接下来说说搜索,搜索有两种类型:一种是 URI 型搜索,另一种是包含了 request body 的搜索。E 提供的 restful api 还有一个特殊的地方,一般在 GET 请求中是不带请求体的,但 E 定义的 GET 请求中带了 request body,存放一些条件参数。
在 URI 型搜索中,显然又分为两类,一类只有 path variable,适用于以 index 为粒度进行搜索,另一类则包含了 query parameter,支持按 field 进行更细粒度的搜索,并且可以设置搜索返回结果的条数、排序方式等。
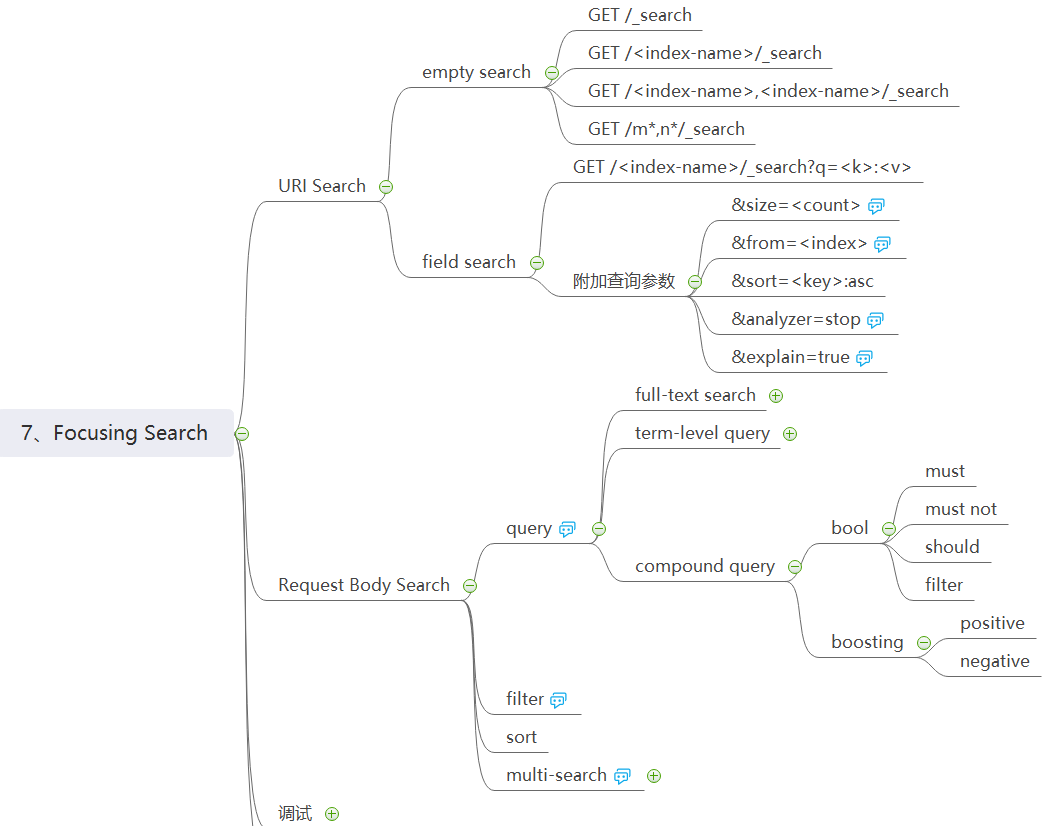
在 Request Body 型搜索中,就可以做得更讲究了。在检索数据时,其实可以分为两种类型:一种是模糊匹配,叫 query,另一种是精确匹配,叫 filter。query 类型可以进行全文检索、词项级别检索、复合检索。在 query 的结果中会给出每条返回结果的 score,表明匹配程度,而 filter 的结果,因为是精确匹配,非黑即白,没有中间态,所以单从性能上说,filter 的性能会更好。
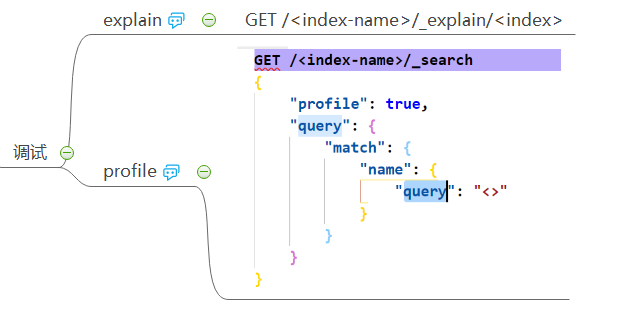
可以通过 explain、profile 来观察整个搜索的过程,以进行调试。
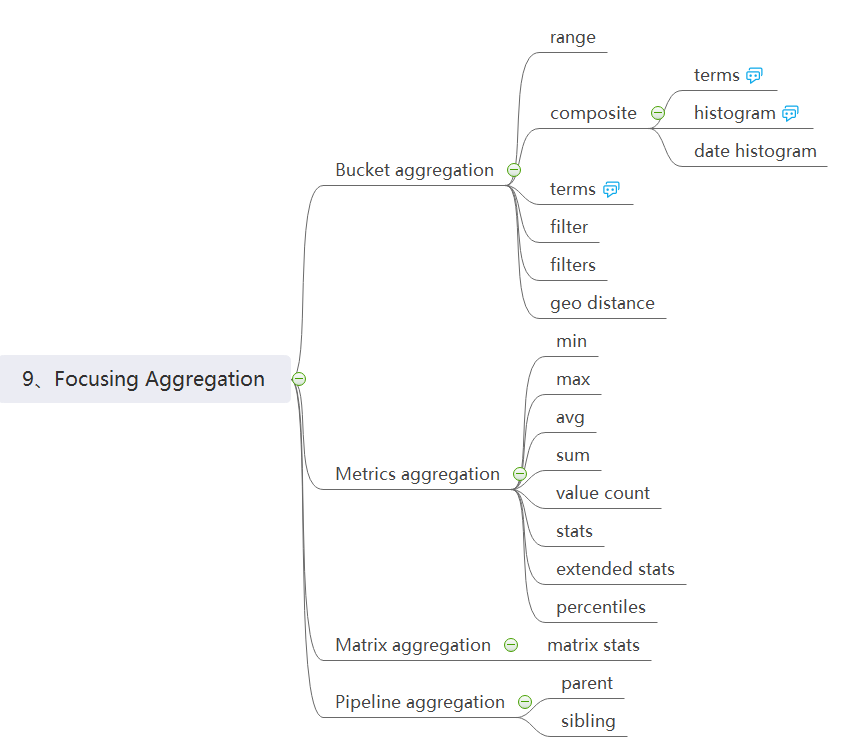
接着来说一说结果聚合,主要有4大类:桶聚合、指标聚合、矩阵聚合、管道聚合。
桶聚合,指定字段,将字段可能取值定义为桶,可以按特定字符串值,也可以按数字区间,比如按 age 字段来划分桶,0-30 岁一个桶,30-60 岁一个桶,60-∞ 为一个桶,得到三个桶,分别聚合得到每个桶的 document 数量。
指标聚合和 sql 里的含义差不多;矩阵聚合作用于一个或多个 numeric 的 field 上,获取矩阵的一些数据;管道聚合,不能直接作用于 document set 上,而必须作用于聚合上。
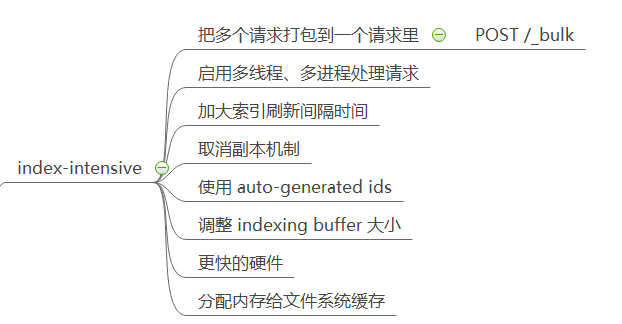
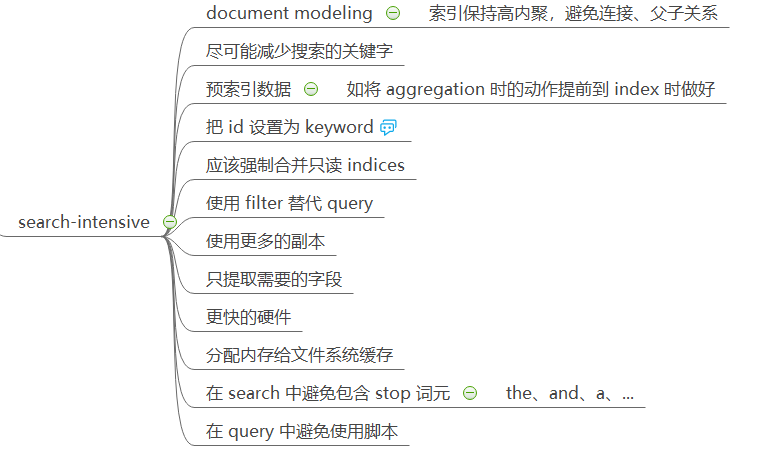
最后是一些提升性能的建议。主要是三个方面:index-intensive、search-intensive、disk-usage。
针对索引密集型的优化建议如下:
针对搜索密集型的优化建议如下:
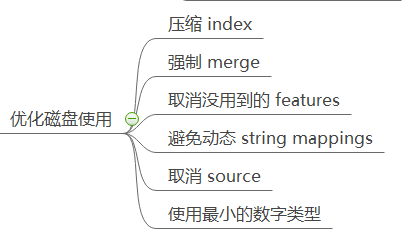
至于磁盘使用
E 还是挺有意思,身上集中了几个热点:索引技术、分布式集群、restful api、log、ML。后续可以再花点时间实践实践。
Reference
《Learning Elasticsearch 7.x》
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
0 条评论