
- 读 | Software Architecture:The Hard Parts 之耦合
- 读 | Software Architecture:The Hard Parts 之代码复用
- 读 | Software Architecture:The Hard Parts 之数据所有权
- 🍗读 | Software Architecture:The Hard Parts 之数据访问
- 读 | Software Architecture:The Hard Parts 之事务
- 读 | Software Architecture:The Hard Parts 之约定
在单体架构中,读数据只要无脑写 SQL 就行,横竖都是怼到一个数据库里,顶多再设计好索引,而当数据分拆到不同的数据库或者由不同的服务控制后,又该怎么做?
有 4 种方法可以把数据再撮合到一起:
- Interservice Communication
- Column Schema Replication
- Replicated Cache
- Data Domain
Interservice Communication
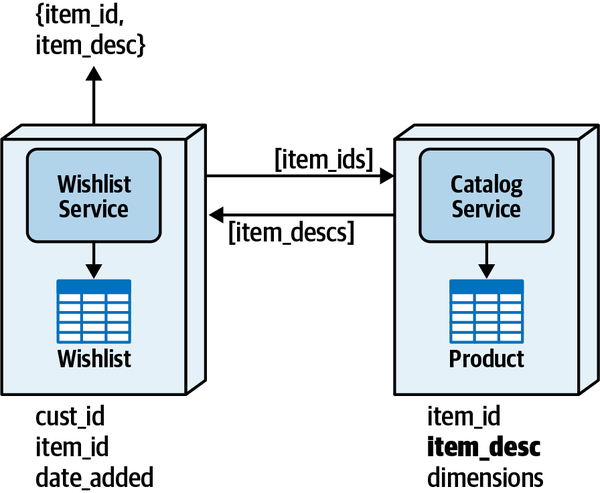
一个服务需要获取非自己管理的数据时,通过实时调用其他服务来获取信息。这种方式简单直接,但存在几个问题:
- 延迟,相比从本地获取,延迟无疑增加了,增加的部分包括:网络延迟+安全检查延迟+数据查询延迟
- 可扩展性,因为功能的实现用到了其他服务,如果本服务扩展了,对依赖服务的负载就会增加,导致被依赖服务也要进行扩展
- 容错,如果依赖服务挂了,本服务就获取不到数据,可能造成可用性问题
- 约定,服务间通信,一定存在约定,增加了复杂性
Column Schema Replication
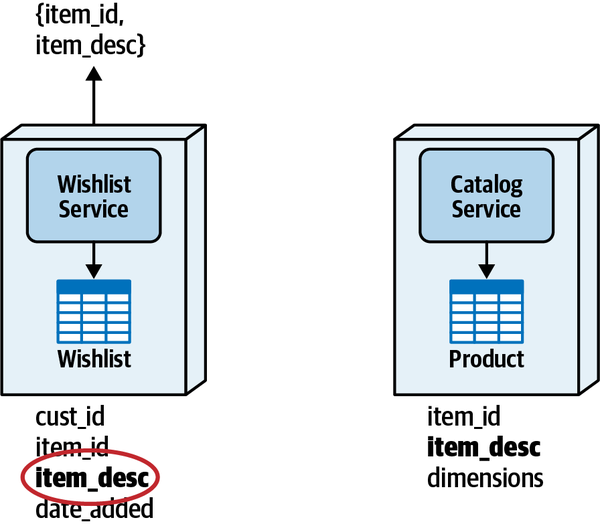
可以从其他服务控制的表中拷贝字段的副本到本地表,没有了服务间的交互,取而代之的是在数据层面进行处理。
带来三个问题:
- 数据同步,需要不停地从另一个服务处同步数据,对实时性没有要求的话一般是异步进行。
- 数据一致性,因为数据同时存在两个地方,是两份,就会始终存在一定的时间间隙,在此期间数据必然不一致,需要根据实际情况选择方案来控制不一致时间间隙的宽度。
- 数据所有权,具有数据所有权才能进行写操作,而这种方案下字段到了服务控制的表里,服务要写谁也拦不住,容易破坏数据所有权关系。
好处就是避免了上一种服务间通信方案中的坏处,适用于数据聚合、制作报表、数据量大、服务响应性要求高、容错性要求较高的情形。
Replicated Cache
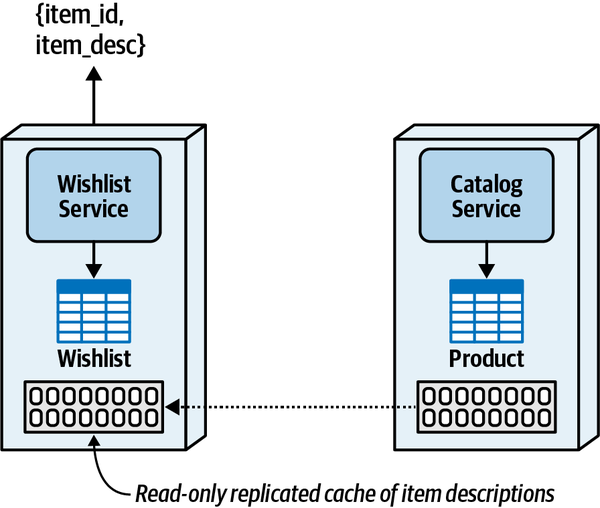
提到缓存时,第一时间会想到两种:本地内存缓存和外置共享缓存。前者是不共享的,后者实质上和从另一个服务获取数据类似(只是数据直接存放在内存,少了从物理介质读取到内存的时间,提高了响应性),存在的问题也类似。
副本缓存也是在每个服务的本地放一个缓存,不过这个缓存是其他服务提供的数据的副本缓存,只能读不能写,会持续和源头保持同步。这个领域的产品有 Hazelcast、Apache Ignite、Oracle Coherence 等。
这种方案提供了很好的响应性、容错性、扩展性。需要注意的有以下几个问题:
- 启动依赖,启动时依赖于缓存,而缓存的填充依赖于源服务,如果源服务处于下线状态,则启动时会一直等待。
- 数据大小,如果副本的数据量比较大,比如 2G,就需要留心所有副本所占用的总内存大小是否在可接受的范围。
- 一致性,如果数据的变动频率很高,将很难保障数据总是处于一致状态。
- 配置管理,服务通过网络了解对方,如果广播和查找范围太广,要花很长时间才能建立好 socket 连接,尤其云环境和容器环境默认对 IP 是放任不管的,比如在 K8S 中我们更常提到 Service Name,而非 IP。
Data Domain
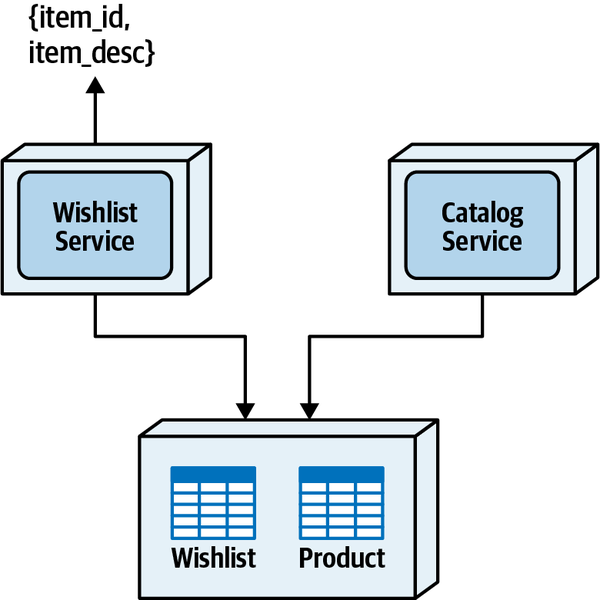
将需要访问的数据放到一个单独的共享 schema 或 database 里,并且不归属于任何服务。服务之间不用耦合了(服务间没有了约定,但数据库表结构成为了约定),数据的一致性和完整性也得到了保障,存在的问题是共享表结构发生变更时的影响范围变大了、服务有能力访问到不应该它访问的数据、数据所有权没有了归属。
0 条评论