
计划趁着假期无人打扰写几篇 《Software Architecture : The Hard Parts》 的读后感,naive 了,只能抽出时间完成多少算多少
- 读 | Software Architecture:The Hard Parts 之耦合
- 🍗读 | Software Architecture:The Hard Parts 之代码复用
- 读 | Software Architecture:The Hard Parts 之数据所有权
- 读 | Software Architecture:The Hard Parts 之数据访问
- 读 | Software Architecture:The Hard Parts 之事务
- 读 | Software Architecture:The Hard Parts 之约定
在单体系统里,代码的复用是通过引入(如 import)或自动注入共享代码(自动注入 class)来实现的。而在分布式架构中,该如何复用?
从软件开发的特点来看,有开发/编译/运行三个阶段,因此针对各个阶段有对应的复用方式,主要存在 4 种:
- 代码拷贝
- 共享 lib
- 共享服务
- sidecar
代码拷贝(开发期)

在同质环境中,可以将复用代码拷贝到各个服务的代码库中,实现代码级的共享。
当有 bug 或重要变更时,很难以高效地方式去更新所有被波及的服务,因此适用于一次性的代码,如某些工具类。这种共享方式也没有版本号来管理共享代码。
共享 lib(编译期)
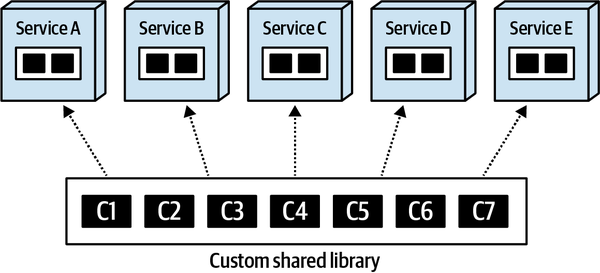
在同质环境中,可以将复用代码封装到共享库文件中,如 jar、dll,在服务的编译阶段引入。
衍生出两个问题:依赖管理、变更控制。
库文件通常都有依赖于版本号的版本管理机制,包括版本号语义、版本启用/迭代/弃用,当有变更发生时,版本号发生了变化,依据版本管理机制,旧版本号进入下线流程,所有使用到该版本的库的服务,都需要进行依赖更新、测试、重新部署,带来大量不必要的工作。
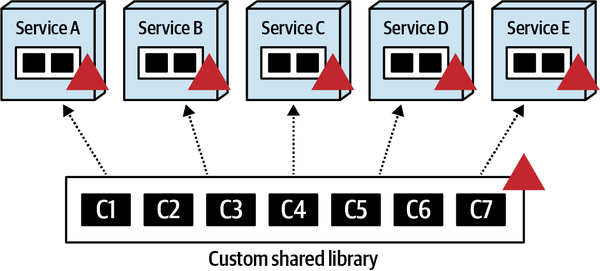
如果库的划分粒度过大,库的变更概率就越大,对周围服务的影响就越大,如下图当 C7 发生变化时,整个 lib 都发生了变化,影响到了服务 A-E。
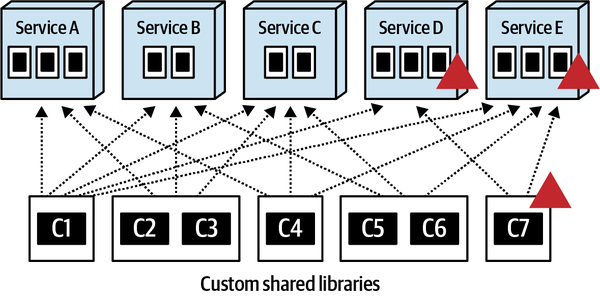
所以共享库也需要尽量划分为功能内聚的小库,这样如下 C7 的变化只影响到服务 D 和 E,调整、测试、重新部署的范围都大大缩小了。
兴一利必有一弊,细分之后会形成一个依赖矩阵,随着服务数量增加,依赖矩阵规模不断膨胀,到最后完全无法管理,所以也需要掌握好粒度。
关于版本管理有两个难点:
- 如何在整个组织内快速、准确地扩散版本变化?其他人如何知道需要升级?变更了什么?影响了哪些服务?影响了哪些团队?
- 如何下线旧版本?根据变更频率、影响范围,对需要同时保留的版本数量、下线周期制定对应的策略。短时间内频繁升级版本,除了带来大量无谓的重复工作、耗尽团队热情,毫无益处。少用 latest 版本号,模棱两可。
ps:永远不要想着一夜之间切换到另一个版本号,后向兼容性需要保障最少支持 2-3 个版本。枯燥乏味的事情请尽量交给机器去自动化,不要用离散工作来折磨人类的大脑。
共享服务(运行期共享)
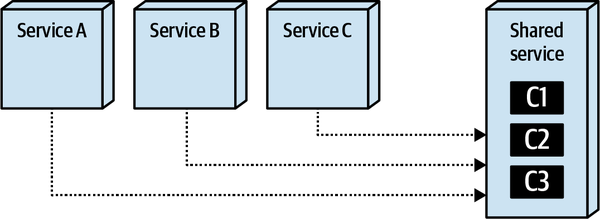
当代码经常发生变化或者环境比较多样化时,将代码单独部署为一个服务,通过服务间调用来共享其计算逻辑。
一个显著的变化是复用代码从各个服务中剥离了,当复用代码发生变化时,不需要重新编译、测试、部署各个服务,只需要重新编译、测试、部署这个单独的共享服务就行了。
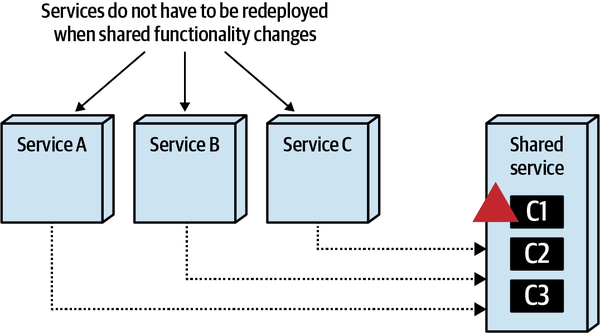
咋看之下似乎这种方式比前两种更好,其实不然。作为单独服务,现在需要考虑以下几个问题:
- Change risk,在共享库方案中,通过编译期版本管理来控制变更风险,而现在,依赖移动到运行期,需要通过对 API 进行版本管理来控制变更风险。版本扩散问题同样存在,同时服务间交互不一定是通过 Restful 方式,也可以是 gRPC 或者消息,增加了额外的功能要求。
- Performance,现在需要跨网络了,增加了网络、安全检查的延迟,对性能有一定影响。
- Scalability,如果非共享服务发生了扩缩,共享服务在一定程度上也要进行扩缩响应,而在前两种方案中,这是自然而然发生的。
- Fault tolerance,考虑共享服务挂了,依赖它的其他服务也无法正常使用。
sidecar(运行期独享)
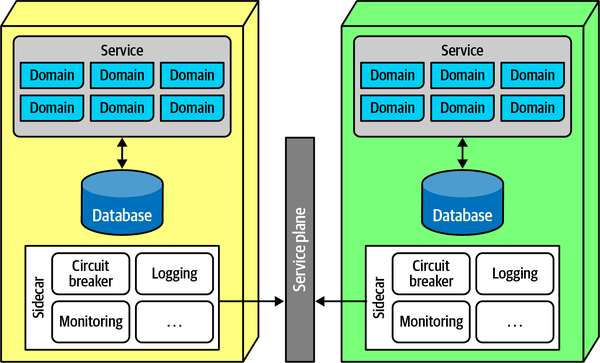
这种方案带有强烈的领域色彩,即将服务关注点拆分为两类:Operational concerns、Domain concerns。
将每个服务都需要的非业务域的代码剥离出来,单独维护,单独运行,但不是作为一个共享服务,而是作为边车进程和业务域进程一起运行。所有服务的非业务边车组成了一个逻辑上的服务平面,进而演化为服务网格。利于提供一个统一的视角来查看各个关注点,类似于提供了一种针对分布式架构的装饰器模式。
0 条评论