
编码的历史由来就懒得介绍了,只需要知道人类处理文本信息是以字符为基本单位,而计算机在最底层只认识 0/1,所以当计算机要为人类存储/呈现字符时,就需要有一个规则,在字符和 0/1 序列之间建立映射关系,这就是编码规则。
因为计算机技术起源于欧美,所以最早的字符编码标准自然而然是基于英语制定的,英语最大的特点是它仅由 26 个大小写字母组合而成,再加上一些特殊字符,就构成了英语的文本世界,其基本字符的总数不会超过 128 个,鉴于 7 个比特位可以有 128 种 0/1 组合,所以用 7 个比特位就足以应付所有需要编码的字符,这样最早的统一标准就诞生了,称为 ASCII(American Standard Code for Information Interchange,美国信息交换标准码)码。在 Linux 系统中输入 man ascii,可以得到如下 ascii 码表:
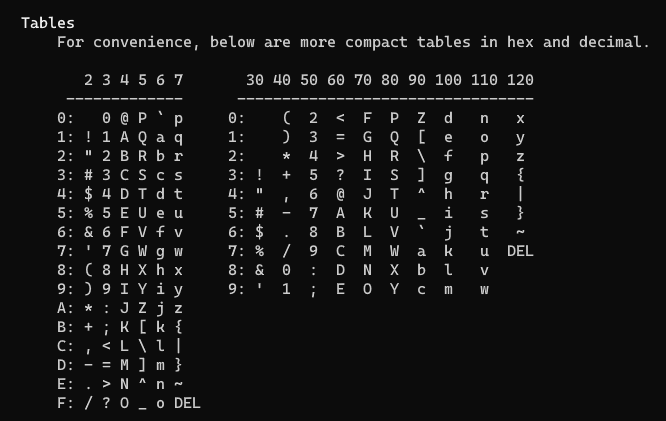
以字符 ‘a’ 为例,16 进制编码为 61,对应的 10 机制表示就是 97,对应的二进制表示为 0110 0001。但西方世界也不是只有英语字母,于是从 1987 年开始,ISO 基于 8 比特位制定了 ISO-8859 系列编码标准,系列中的每一个标准用到的编码位数都不超过 8 位。
按 ascii 和 ISO-8859 编码标准的规定,其包含的字符都可以用一个字节(8 比特)表示,在存储时也就只占用一个字节,但世界上并不只有西方文字,还有很多其他类型。
最典型就是中文,中文是典型的象形文字,而且是世界上使用人数最多的文字,常用汉字数量就不止 1000 个,指望 ascii 是不行的——就算把存 ascii 码的 8 个比特全用来表示中文,也不够,所以也发展出了自己的一套编码规范:
- 1980 年,中国搞了自己的编码方案 GB/T 2312(GB/T 代表推荐性国家标准,可以参考前一篇 博文 里的介绍),一般简称 GB2312。
- 1993 年,国际标准化组织 ISO 制定了编码标准 ISO/IEC 10646-1:1993,国内予以承认,并编号为 GB 13000.1-1993。
- 1995 年,国内基于 GB2312 扩展了一套编码方案 GBK(汉字内码扩展规范),并收录了 GB13000.1 和 Big5(由台湾资讯工业策进会在1984 年制定)中的汉字,微软在 Windows 95、Windows NT 3.51 中进行了实现,称为 Code Page 936。
- 2000 年,制定了国标 GB 18030-2000,目前已作废。
- 2005 年,制定了国标 GB 18030-2005,为现行的 GB18030 标准。
- 2022 年,制定了国标 GB 18030-2022,将在 2023年8月1日生效。
GB2312、GBK、GB18030 就是目前老系统中常用的三种中文编码方案。
这还只是中文,当我们把眼界放大到整个地球(球外暂不考虑),仅仅东亚就还有日文、韩文,还有中亚、中东、非洲等等国家和地区的文字都需要编码进计算机。如此多的国家和地区,如此多的语言文字,再各自搞一套就真乱成一锅粥了,除了 ASCII 被默认继承,同一个或两个字节,在不同的编码标准中基本就代表着不同的字符,必须要找到正确的标准才能进行解码,在计算机互通的情况下,这变得很复杂。一套统一的、国际化的编码标准势在必行,尤其对于跨国公司开展全球化业务,所以 Unicode 的诞生可以说是名正言顺。
第一版 Unicode 早在 1991 年就发布了,目前已发展到第 15 版。

在早期的 ASCII 编码标准中,因为一个 8 位的字节就可以表示完字符集中所有的字符,而字节也正是计算机中进行运算、存储的基本单元(如 8 位是传统的加法器、锁存器、数据选择器的输入/输出),所以编码、运算、存储时没什么可争议的。但当被编码的字符数量超过了一个字节可以有的组合数时,就变得有趣了。
举个例子,假设我现在有 257 个字符需要编码到同一个编码标准中,由于 8 位最多只有 256 种组合(0-255),对于第 257 个字符,至少要再加 1 位,达到 9 位,才能给这个多出来的字符一个唯一编码(如 1 0000 0000),但我们是用数字来对字符进行编码的,在计算机中表示数字的基本单元是 8 位的字节(不存在 9 位的基本单元),也就是说,要想在计算机里进行处理,必须把第 257 个字符呈现为 2 个字节(如 0000 0001 0000 0000)。以此类推,当我需要表示出第 65536 个字符时,在计算机里至少需要 3 个字节,如果字符数量继续增加,就得按这个逻辑继续增加字节数。
从举的例子来看,计算机中的字符编码虽然比实际编码多了一些比特位,因为只是高位补 0,两者的值还是一致的,实际使用中则没有这么简单。
让我们再次回到例子中,现在我有 257 个字符,第 257 个字符的十进制编码值是 256,在计算机中至少要用两个字节表示 —— 0000 0001 0000 0000。现在我要表示(十进制编码值是 1 的)第 2 个字符,在计算机中既可以用 1 个字节表示—— 0000 0001,也可以用 2 个字节表示 —— 0000 0000 0000 0001。那么,是用 1 个字节,还是 2 个字节?
如果用 2 个字节,每个字符编码时所用的字节数就是一样的,便于寻址,代价是对资源的浪费。如果内存、存储成本昂贵,则固定 2 字节的方案就值得商榷。
如果用 1 个字节,就存在两种情况,有的字符用 1 个字节表示,有的字符(必须)用 2 个字节表示,字符对应的字节数不固定,这时就需要在第 1 个字节中告诉计算机,读到当前字节就可以开始解码,还是要再读取 1 个字节,用 2 个字节来解码。需要表示这个信息,可以基于固有的大小属性进行表示,也可以添加额外的位来表示。
可以看到,编码值和在计算机中的实际编码所要表达的含义具有差别(前者目的是做符号的唯一数字标识,后者还要考虑计算机本身的限制),因为 Unicode 要收录所有的字符到同一个编码标准中,必然存在超过一个字节的情况,所以分得很清楚,前者被称为 Code Point(also called Character Number or Code Position or Unicode Scalar Value),后者被称为 Code Units,在前面介绍的几种编码标准(ASCII、GB2312、GBK、GB18030、Big5)中,每一种标准的 Code Point 和 Code Units 都是确定的。但在 Unicode 中,只规定了 Code Points,没有规定 Code Units,单说 Unicode,只是一套统一的字符集(UCS,Universal Character Set)和它对应的 Code Points(U+0000 ~ U+10FFFF),并不包含在计算机中实际是怎么编码表示的。只有 UTF-8、UTF-16、UTF-32 时,才表示在使用 Unicode 字符集的基础上,在计算机中字符具体的 Code Units 是怎样的。三种方案的差别就在于 Code Units 的大小,实际使用中根据需要进行选择。
简单看一下 UTF-8 中对 Code Units 是如何规定的。

UTF-8 中所有字符的 Code Units 长度并不一致:
- 1 字节,第一个字节的高 1 位为 0,兼容 ASCII;
- 2 字节,第一个字节的高 2 位为 1,第 3 位为 0;
- 3 字节,第一个字节的高 3 位为 1,第 4 位为 0;
- 4 字节,第一个字节的高 4 位为 1,第 5 位为 0。
而在 UTF-16 中,字符有 2 字节、4 字节两种长度;在 UTF-32 中,所有字符都用 4 字节。
以 ‘蛤’ 为例,在 Unicode 中的 Code Point 是 U+86E4,在 UTF-8、UTF-16(有大小端之分)、UTF-32(有大小端之分)下的表示分别是:
- UTF-8:E8 9B A4(11101000 10011011 10100100,把背景高亮部分抽出来就是 10000110 11100100,也就是 16 进制的 86 E4)
- UTF-16BE:86 E4
- UTF-32BE:00 00 86 E4
0 条评论